
Part 1: The Problem & Uber's Approach
The Challenge of Handling 1 Million Location Requests per Second
Have you ever wondered how Uber and similar ride-hailing services handle millions of ride requests per day—sometimes even per second? How do they instantly match a client/rider with the best driver without making you wait an eternity? Well, let’s deep dive and explore how Uber pulls this off with insane efficiency.
Uber operates in cities across the globe, processing millions of ride requests per second. When a rider requests a trip, the system needs to quickly find the nearest available driver, factoring in location accuracy, real-time traffic, and estimated arrival times.
However, brute-force searching through every driver’s latitude-longitude coordinates in a database is computationally expensive and slow. If Uber had to compare each rider's location against every driver's coordinates manually, the system would collapse faster than your Wi-Fi at a tech conference.
So, how does Uber make location searches super fast while maintaining accuracy? Welcome to H3 Geospatial Indexing, the hero we didn't know we needed.
The Limitations of Traditional GPS Coordinate Searches
Imagine if Uber didn’t use any optimization and had to match riders and drivers with raw GPS coordinates:
- Searching through millions of lat-long pairs for every request.
- Complex distance calculations for every driver within a city.
- Inconsistent results due to varying street layouts and traffic conditions.
This would be like looking for your lost AirPods in a city without Find My Device – a painful, frustrating mess. Using raw latitude and longitude might work for a small-scale taxi service, but for Uber and similar gigantic world wide car hailing service, this approach would be too slow and inefficient.
Uber needed a way to index locations efficiently, allowing quick lookups and nearby driver searches without setting their servers on fire.
Uber’s Solution: H3 Geospatial Indexing
To solve the problem, Uber developed really cool geospatial indexing system ie H3, a system that divides the Earth's surface into a grid of hexagonal cells. Each cell has a unique index, making it easy to group locations and quickly find nearby drivers.
Why Hexagons? (And Not Squares or Triangles?)
Uber chose hexagons for the same reason that nature does—they're just better. But let’s break it down the concept:
First Question is Why Hexagons? Why not Triangle, Squares and heck even Decagon? 😄
- Squares? Yeah, they cover space efficiently, but the distances between their neighbors vary. This makes spatial calculations awkward—like trying to run in flip-flops.
- Triangles? Not even worth considering. Sure, they look cool in geometry class, but they make terrible grids due to their uneven coverage.
- Hexagons? Now we’re talking! They have equal spacing between all neighbouring cells, making searches for “the closest driver” way more efficient. Plus, they avoid gaps and overlaps, unlike squares, which create alignment nightmares at scale.
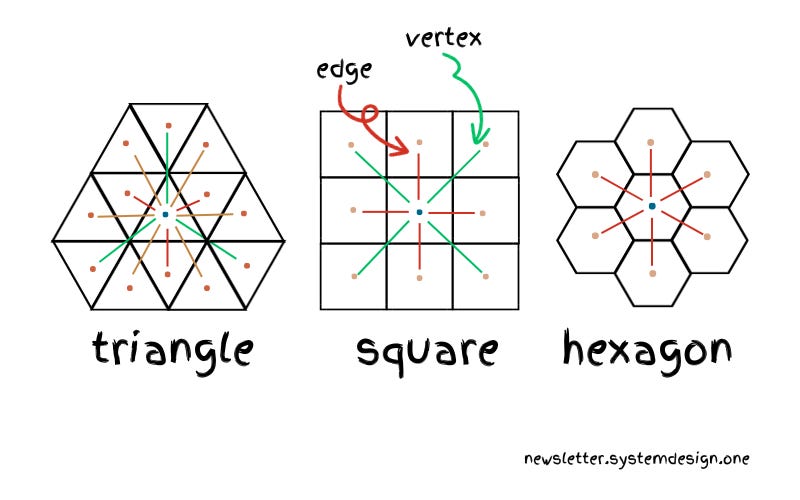
This visual shows how different grid shapes handle connectivity. Squares introduce inconsistencies in distances, triangles create inefficient paths, while hexagons provide uniform neighbour spacing—making them the best choice for geospatial indexing. – credit goes to systemdesign.one
How Uber Uses H3 for Driver Matching
Here’s how Uber efficiently finds nearby drivers:
- Convert a driver’s latitude and longitude into an H3 index (a hexagon ID).
- Store the driver’s location in an optimized database like Redis.
- When a rider requests a ride, convert the rider’s location to an H3 index.
- Search for nearby drivers by looking up adjacent hexagons (using a function called
kRing). - Sort drivers by Estimated Time of Arrival (ETA) instead of just distance, because what good is the closest driver if they’re stuck behind a horse-drawn carriage?
By using this hexagonal grid system, Uber dramatically reduces search complexity, making it possible to handle millions of ride requests per second.
What’s Next?
In the next part of this series, we’ll dive deeper into how H3 indexing works under the hood and why Uber chose a specific resolution level (Resolution 9)
Stay tuned for Part 2: How H3 Works Under the Hood, where things get even geekier (but still fun).